
Big Data
Ingeniero de software especializado en sistemas de información empresarial con el objetivo principal de mejorar la eficiencia y la eficacia de las operaciones empresariales a través del uso de tecnologías y soluciones informáticas.

1.Introducción
1.1 Antes del big data
¿Cómo se gestionaban los datos antes de la era del big data?
Antes del surgimiento de big data, la mayoría de los datos eran estáticos y se guardaban en sistemas de bases de datos relacionales, como Oracle o Microsoft SQL Server. Estos sistemas eran eficientes para almacenar y recuperar información estructurada, pero tenían dificultades para manejar grandes volúmenes de datos no estructurados.
Además, la tecnología de la información en ese momento se centraba en la integración de sistemas y la automatización de procesos empresariales, y no había una gran necesidad de analizar grandes cantidades de datos en tiempo real. La mayoría de las empresas confiaban en los informes periódicos y las estadísticas para tomar decisiones estratégicas. Otro factor importante a considerar es que la tecnología de la información en ese momento no tenía la capacidad de procesar y analizar grandes cantidades de datos en tiempo real. La capacidad de almacenamiento y la potencia de procesamiento eran limitadas, lo que hacía que el análisis de datos fuese un proceso lento y costoso. En resumen, antes de big data, los datos eran estáticos, se guardaban en sistemas de bases de datos relacionales y la tecnología de la información se centraba en la integración de sistemas y la automatización de procesos empresariales, sin una gran necesidad de analizar grandes cantidades de datos en tiempo real.
1.2 Definición de big data
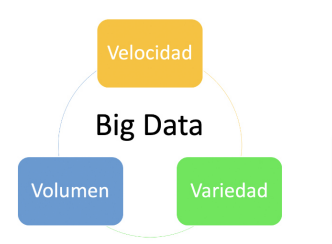
Figura 1 Las tres variables de los macro-datos o Big data. Fuente: (https://interactivechaos.com/es/blog/big-data-y-el-modelo-de-las-tres-vs)
¿Qué son exactamente los big data, llamados en castellano macro datos? La definición de big data es la de datos que:
- contienen mayor variedad,
- llegan en volúmenes cada vez mayores y
- se procesan con mayor velocidad.
Esta tríada se conoce también como “las tres V”. (2001. Doug Laney, de Gartner, define las 3 V’s del Big Data)
En pocas palabras, big data o macro datos son conjuntos de datos más grandes y complejos, especialmente procedentes de nuevas fuentes de datos. Estos conjuntos de datos son tan voluminosos que el software tradicional de procesamiento de datos simplemente no puede gestionarlos. Pero estos volúmenes masivos de datos pueden utilizarse para resolver problemas empresariales que antes no habrían podido abordarse.
El campo del big data ha evolucionado desde la disciplina del análisis estadístico hasta las actuales tecnologías avanzadas de “data lakes” o lagos de datos. En este artículo describiremos cómo hemos llegado hasta aquí, los retos que el big data ha planteado a lo largo del camino y cómo las organizaciones están utilizando los “data lakes” y cómo las organizaciones las están utilizando para obtener más valor de los datos que nunca.
Las raíces de big data provienen de business intelligence llamada en castellano inteligencia empresarial, un término que IBM (PDF) acuñó en 1958, definiéndolo como: «la capacidad de aprender las interrelaciones de hechos presentados de tal manera que guíen la acción hacia un objetivo deseado» (IBM, 1958).
Durante los años 60 y 70, hubo un gran progreso en la tecnología de datos con el surgimiento de los mainframes y las bases de datos. A mediados de los años 80, los ordenadores personales se popularizaron y se introdujo la informática cliente-servidor, lo que llevó al uso de bases de datos relacionales y a la aparición del lenguaje SQL (Structured Query Language). Con estos avances, tanto la utilidad como el volumen de datos aumentaron. A principios de los años 90, el crecimiento de Internet, el comercio electrónico y las tecnologías de búsqueda impulsaron la recopilación de datos. La necesidad de inteligencia empresarial en medio de estos grandes volúmenes de datos llevó a las empresas a crear almacenes de datos especializados y optimizados para la analítica. Estos almacenes de datos se utilizaron para almacenar datos revisados procedentes de una amplia variedad de fuentes.
En la actualidad, los almacenes de datos se han convertido en la infraestructura básica que utilizan las empresas para completar informes, realizar análisis, hacer predicciones y prospectiva empresarial, y apoyar la toma de decisiones sobre evidencias observadas.
1.3 La era actual: explorando datos para obtener información
En el 2005, comenzamos a dar cuenta de la cantidad de datos que los usuarios generaban a través de las redes sociales y otros servicios en línea. Esta gran cantidad de datos, derivados del enorme aumento de la información en internet, tanto estructurados como no estructurados, eran demasiado para las tecnologías existentes y para procesarlos de manera útil y económica. Por todo ello, surgieron diversas iniciativas que intentaban superar las crecientes limitaciones en la extracción de datos y la interpretación informativa.
- Google desarrolló un nuevo enfoque llamado MapReduce, que permitía el procesamiento de grandes cantidades de datos. Con el tiempo, esto evolucionó en Hadoop, un marco de código abierto que permitía el almacenamiento y procesamiento de datos a gran escala.
- Hadoop, por su parte, permitió la creación de nuevos usos para los datos, como la creación de vistas completas de los clientes en el comercio electrónico. Además, Hadoop se expandió con herramientas adicionales para mejorar su capacidad y eficiencia.
- Posteriormente, Spark se hizo popular por su velocidad de cálculo, escalabilidad y programabilidad para el procesamiento de grandes volúmenes de datos, especialmente en aplicaciones de streaming de datos, grafos, aprendizaje automático e inteligencia artificial. Además, Spark procesa los datos en memoria, lo que permite un rendimiento más rápido y eficiente.
2. El mundo actual y el big data
En la sociedad de hoy, el big data es un factor importante que está influyendo en muchos aspectos de nuestras vidas. Debido a la cantidad de información que generamos a través de las redes sociales, servicios en línea y otros medios, existe una gran cantidad de datos disponibles para ser procesados y analizados. La tecnología ha avanzado para poder manejar estos grandes volúmenes de información, lo que ha permitido a las empresas y organizaciones tomar decisiones más informadas y mejorar sus procesos. Además, la inteligencia artificial y el aprendizaje automático están siendo utilizados cada vez más para analizar y utilizar estos datos. Sin embargo, también existen preocupaciones legales y de privacidad, como la regulación de la Unión Europea sobre protección de datos personales (REGLAMENTO 2016/679 DEL PARLAMENTO EUROPEO Y DEL CONSEJO de 27 de abril de 2016). En resumen, el big data es una parte integral del mundo en el que vivimos y está teniendo un impacto significativo en muchos aspectos de la sociedad.
Es difícil tener una visión completa sobre cómo se está utilizando el big data en la actualidad debido a la gran cantidad de tecnologías y aplicaciones que existen. Sin embargo, hay varios factores clave en la industria actual, incluyendo la tecnología actual, la normativa GDPR y el aprendizaje automático y la inteligencia artificial.
2.1 Datos, Información y Conocimiento
Es importante conocer y distinguir las diferencias entre estos tres conceptos clave para el big data:
- Datos: Representan hechos, cifras o estadísticas que no tienen contexto ni significado propio. Son la materia prima para crear información. Por sí solos, no brindan conocimiento alguno.
- Información: Son los datos organizados, analizados y presentados de una manera que los hace significativos y útiles para los usuarios. Proporcionan contexto y permiten entender relaciones y patrones.
- Conocimiento: Es el resultado de combinar información con experiencia, valores, habilidades y juicio crítico. Es el entendimiento profundo y aplicado que se obtiene a partir de la información y permite la toma de decisiones y la resolución de problemas.
Todos estos términos tienen una relevancia importante al interpretar la información en el mundo del big data.
Hay un costo entre convertir datos en información, e información en conocimiento.
En el mundo big data, la cantidad de datos ha explotado de forma exponencial, pero no siempre más datos significa más información. Se ha producido también el efecto contrario, el de la desinformación. La posibilidad de generar datos también ha permitido a ciertas personas generar desinformación.
A la vez que se genera información, esta puede ser usada como entradas de datos para producir más información en conjunción con otros sistemas de información.
La capacidad de generar conocimiento también se verá incrementada, posibilitando generar más conocimiento. Todo esto combinado nos permite crear sistemas que tienen capacidad de predecir tendencias, cruzar la información de formas nunca vistas y generar conocimiento de una forma nunca antes vista.
A dónde llegaremos es algo que aún no está claro, pero la potencia de cálculo sigue creciendo y las expectativas llevan a crear un sistema de inteligencia artificial que supere a la de un humano.
2.2. Evolución tecnológica y herramientas de interés
Apache Flink y Apache Spark son dos plataformas de procesamiento de big data que se utilizan comúnmente en la industria. Ambas plataformas permiten el procesamiento distribuido de grandes volúmenes de datos en tiempo real y en lotes, lo que les permite a las empresas analizar y obtener información valiosa a partir de estos datos.
Flink es un motor de flujo de datos de código abierto que se utiliza para procesar grandes volúmenes de datos en tiempo real. Flink es muy eficiente en términos de tiempo de ejecución y escalabilidad, lo que lo hace ideal para aplicaciones que requieren una respuesta rápida y una escalabilidad sin interrupciones.
Spark, por otro lado, es un marco de procesamiento de datos de código abierto que se utiliza para procesar grandes volúmenes de datos en tiempo real y en lotes. Spark es conocido por su capacidad de procesar datos en memoria, lo que lo hace ideal para aplicaciones que requieren una velocidad de procesamiento rápida. Spark también ofrece una amplia gama de herramientas y librerías para el aprendizaje automático, el análisis de datos y la inteligencia artificial, lo que lo hace una plataforma atractiva para los usuarios que buscan soluciones completas para el procesamiento de big data.
En resumen, tanto Flink como Spark son plataformas efectivas para el procesamiento de big data, cada una con sus propias fortalezas y debilidades. La elección entre una y otra depende de las necesidades específicas de una empresa y del uso que se le dará a los datos.
2.3 La inteligencia artificial en la generación de lenguaje natural
El big data o los macro datos, y el aprendizaje automático (conocido como Machine Learning, ML, en inglés) son áreas que se complementan y pueden aprovecharse mutuamente. El big data proporciona una gran cantidad de datos para entrenar modelos de aprendizaje automático, mientras que los modelos de aprendizaje automático pueden ayudar a extraer valor de los datos de big data.
Por ejemplo, con un gran conjunto de datos de compras en línea, un modelo de aprendizaje automático podría analizar patrones en las compras para hacer recomendaciones personalizadas para los clientes. También podría ayudar a detectar patrones fraudulentos en las transacciones de pago.
Por ejemplo:
a) La gestión de datos de escolarización y la prospectiva en la planificación educativa.
b) La recogida de datos de resultados académicos y propuestas de políticas educativas de apoyo a ciertas áreas curriculares.
c) La identificación de variables socio-familiares y su correlación con el fracaso escolar, el abandono temprano o el absentismo escolar.
En cuanto al uso de la Inteligencia artificial en el aula, destaca en los últimos meses el desarrollo de los sistemas conversacionales, a partir de algoritmos que detectan frecuencias de uso y patrones lingüísticos, como el GPT-Chat. Actualmente ChatGPT-3.5 se halla en proceso de aprendizaje y desarrollo: es un modelo de lenguaje entrenado por OpenAI que puede ser utilizado para responder preguntas y realizar tareas comunicativas complejas (p.e. explicar, comparar, preguntar, resumir, sintetizar, crear respuestas personalizadas o adaptadas a perfiles de edad, estilos lingüísticos, o preferencias culturales diferentes).
En esta línea de desarrollo, ChatGPT puede simular en sus respuestas, con cierto éxito, una adaptación al contexto proporcionado por el usuario (el “prompting”), y emitir propuestas originales ajustadas a distintos parámetros que debe dar el usuario (p.e. utilizar diversos idiomas, escribir como un autor concreto, explicar conceptos matemáticos con ejemplos de la vida cotidiana, utilizar jergas o restricciones de lèxico, proponer preguntas de examen, sugerir regalos para una persona determinada, proponer nombres para un hijo, responder a situaciones simuladas, etc.). Aunque no es un modelo de aprendizaje automático específicamente diseñado para procesar big data, puede ser utilizado para responder preguntas relacionadas con big data y aprendizaje automático, ya que ha sido entrenado con una gran cantidad de texto y tiene conocimiento en varios temas, incluyendo big data y aprendizaje automático.
3- Experiencia práctica: un caso real
La industria del big data se mueve de manera privada y discreta. Es difícil describir un caso de uso real debido a los acuerdos de confidencialidad, pero vamos a intentar describir un ejemplo que se ajuste a este campo de conocimiento.
En este artículo nos centraremos en la gestión empresarial del mismo Big Data, dado que su procedencia parte de este sector y una mejor comprensión y contextualización por parte del lector. Sin embargo, se abordará el enfoque educativo desde el artículo de Big Data en Educación de la Comunidad Autónoma de Andalucía, en el que veremos cómo este concepto empresarial se incorpora al mundo educativo y la potencialidad que desde nuestro ámbito podemos encontrar en este concepto.
Imagine que manejamos una tienda en línea que vende diversos artículos. Conocemos las interacciones de los usuarios con la página web, su navegación, opiniones e historial de compras. Además, tenemos suficiente información del usuario para segmentarlo basándonos en su edad, ubicación, horarios de uso y datos demográficos. El sistema también es multilingüe, lo que plantea desafíos en la identificación de patrones debido a diferencias culturales. En resumen, tenemos una gran cantidad de información que es difícil de definir y abarcar debido a la complejidad y variedad de datos que se generan (las tres V). ¿Qué podemos hacer con esta información para mejorar las ventas?
1- Conoce tus métricas
Es la importancia de comprender y medir los datos e indicadores clave que se relacionan con el desempeño y éxito de una empresa o proyecto. Es decir, es una invitación a identificar y seguir de cerca los números y estadísticas que ayuden a entender la salud y progreso de un negocio, con el fin de tomar decisiones más informadas y ajustar estrategias en consecuencia. En resumen, conocer tus métricas significa tener una visión clara y objetiva de la situación actual, lo cual es fundamental para alcanzar tus objetivos y lograr un crecimiento sostenible.
Esta tarea se puede hacer de forma parcial, pero es irrealista que un sistema de big data se pueda construir sin tener los conocimientos básicos del negocio
2- Segmentación de clientes
La segmentación de clientes es un proceso que consiste en dividir a un grupo de consumidores en subgrupos con características similares para mejor comprender y satisfacer sus necesidades y preferencias. Esto se logra a través del análisis de datos demográficos, patrones de comportamiento de compra, preferencias y otros factores relevantes.
3- Predicción del valor de vida del cliente
La predicción del valor de vida del cliente (CLV, por sus siglas en inglés) es una técnica de análisis que se utiliza para estimar la cantidad de dinero que un cliente le generará a una empresa durante todo su ciclo de vida. Esta predicción se basa en una variedad de factores, incluyendo la frecuencia y el tamaño de las compras, la duración de la relación con el cliente, la probabilidad de retener al cliente y la probabilidad de que recomiende a otras personas la empresa. Conocer el CLV de un cliente es importante porque permite a las empresas tomar decisiones informadas sobre cómo invocar en un cliente, y cómo maximizar su valor para la empresa a lo largo del tiempo.
4- Predicción de cancelación
La predicción de cancelación es el proceso de identificar los clientes que tienen una alta probabilidad de cancelar un producto o servicio en un futuro próximo. Esto se logra analizando patrones de comportamiento, datos demográficos y otros factores relevantes. La predicción de cancelación permite a las empresas tomar medidas proactivas para retener a los clientes y prevenir la pérdida de ingresos.
5- Predicción del día de compra siguiente
La predicción del día de compra siguiente es un proceso en el cual se utilizan datos del historial de compra de los clientes, patrones de comportamiento y otra información relevante para predecir con precisión el día en que un cliente es más probable que realice una compra en el futuro. Esto permite a las empresas planificar y optimizar sus estrategias de marketing y ventas para aprovechar al máximo las oportunidades de compra y mejorar su relación con los clientes. La predicción del día de compra siguiente es una herramienta valiosa para mejorar la eficiencia y la efectividad de las operaciones comerciales.
6- Predicción de ventas
La predicción de ventas es el proceso de utilizar datos históricos, análisis y algoritmos de inteligencia artificial para estimar las futuras ventas de un producto o servicio. Este proceso puede ayudar a las empresas a planificar su producción, almacenamiento y presupuesto de marketing. Además, también puede ayudar a identificar tendencias y oportunidades de crecimiento en el mercado. La precisión de la predicción de ventas depende de la calidad y cantidad de datos disponibles y de la eficacia de los algoritmos utilizados.
7- Modelos de respuesta del mercado
Los Modelos de respuesta del mercado son herramientas de análisis que permiten predecir la respuesta del mercado a una acción específica, como una campaña de marketing, un aumento de precios o un cambio en la oferta de productos. Estos modelos utilizan técnicas estadísticas y de inteligencia artificial para analizar datos de mercado y del comportamiento del consumidor, y luego hacer predicciones sobre cómo reaccionarán los consumidores a diferentes estrategias de marketing. Los modelos de respuesta del mercado pueden ser útiles para tomar decisiones informadas sobre el posicionamiento de productos, la segmentación de mercado y la planificación de la demanda.
8- Modelado de aumento
El modelado de aumento es una técnica de análisis de marketing que se utiliza para predecir qué clientes son más propensos a responder positivamente a una campaña de marketing y qué impacto tendrá en sus comportamientos de compra. Esto se logra al comparar el comportamiento de los clientes que recibieron la campaña con aquellos que no la recibieron, lo que permite identificar los efectos netos de la campaña en las compras y las conversiones. El modelado de aumento es útil para maximizar el impacto de las inversiones en marketing y mejorar la eficiencia de la campaña.
4.¿Cómo se puede implementar estos procesos?
Hay diversos algoritmos relevantes para gestionar los macrodatos que nos ayudan a identificar, predecir y tomar decisiones sobre las conductas de los usuarios de cualquier servicio.
4.1. Los algoritmos relevantes de procesos de modelado de conducta y estudio de usuarios
Hay seis tipos importantes de algoritmos de aprendizaje automático: algoritmos explicativos, algoritmos de minería de patrones, algoritmos de aprendizaje en conjunto, algoritmos de agrupamiento, algoritmos de series temporales y algoritmos de similitud.
Algoritmos explicativos
Estos algoritmos ayudan a identificar las variables que tienen un impacto significativo en el resultado de interés. Permiten entender las relaciones entre las variables en el modelo, en lugar de solo utilizar el modelo para hacer predicciones sobre el resultado. Ejemplos incluyen Regresión Lineal/Logística, Árboles de Decisión, Análisis de Componentes Principales, LIME y Shapley.
Algoritmos de minería de patrones
Estos algoritmos se utilizan para identificar patrones y relaciones dentro de un conjunto de datos. Ejemplos incluyen el algoritmo Apriori, Redes Neuronales Recurrentes, LSTM, SPADE y PrefixSpan.
Algoritmos de aprendizaje en conjunto
Estos algoritmos combinan las predicciones de múltiples modelos para hacer predicciones más precisas que cualquiera de los modelos individuales. Ejemplos incluyen Random Forest, XGBoost, LightGBM y CatBoost.
Algoritmos de agrupamiento
Estos algoritmos se utilizan para agrupar similares datos juntos. Ejemplos incluyen K-Means, Hierarchical Clustering y DBSCAN.
Algoritmos de series temporales
Estos algoritmos se utilizan para analizar y predecir patrones en datos temporales. Ejemplos incluyen ARIMA y SARIMA.
Algoritmos de similitud
Estos algoritmos se utilizan para medir la similitud entre los datos. Ejemplos incluyen KNN y SVM. Es fácil encontrar documentación, ejemplos de cualquiera de ellos en internet. Este es un cambio sutil de la era actual, junto con la complejidad de estos algoritmos, es fácil encontrar implementaciones, algoritmos adaptados y propuestas híbridas.
Algo que no se menciona en este artículo sobre el código abierto. Sin embargo, cuando se trata de grandes cantidades de datos, hay una gran cantidad de información disponible, que daría para otro artículo.
Bibliografía y enlaces relacionados
BM(1958). The Reservoir of Information for Control Units. Proceedings of the Eastern Joint Computer Conference, 12, 101-112.
Apache Spark. (s. f.). Apache Spark.
Apache Flink. (s. f.). Apache Flink.
Descargar PDF del Informe. Informe-Tendencias-ODITE-2022.pdf (60746 descargas )