
Enginyer de programari especialitzat en sistemes d’informació empresarial amb l’objectiu principal de millorar l’eficiència i l’eficàcia de les operacions empresarials mitjançant l’ús de tecnologies i solucions informàtiques.

1.Introducció
1.1 Abans del big data
Com es gestionaven les dades abans de l’era del big data?
Abans del sorgiment de big data, la majoria de dades eren estàtiques i es guardaven en sistemes de bases de dades relacionals, com ara Oracle o Microsoft SQL Server. Aquests sistemes eren eficients per emmagatzemar i recuperar informació estructurada, però tenien dificultats per manejar grans volums de dades no estructurades.
A més, la tecnologia de la informació en aquell moment se centrava en la integració de sistemes i l’automatització de processos empresarials i no hi havia una gran necessitat d’analitzar grans quantitats de dades en temps real. La majoria de les empreses confiaven en els informes periòdics i les estadístiques per prendre decisions estratègiques. Un altre factor important que cal considerar és que la tecnologia de la informació en aquell moment no tenia la capacitat de processar i analitzar grans quantitats de dades en temps real. La capacitat d’emmagatzematge i la potència de processament eren limitades, cosa que feia que l’anàlisi de dades fos un procés lent i costós. En resum, abans de big data, les dades eren estàtiques, es guardaven en sistemes de bases de dades relacionals i la tecnologia de la informació se centrava en la integració de sistemes i automatització de processos empresarials, sense una gran necessitat d’analitzar grans quantitats de dades en temps real.
1.2 Definició de big data
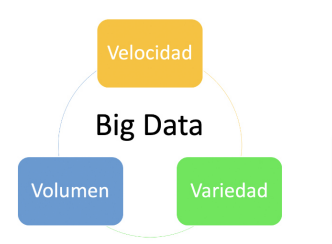
Figura 1 Les tres variables de les macrodades o Big data. Font: (https://interactivechaos.com/es/blog/big-data-y-el-modelo-de-las-tres-vs)
Què són exactament els big data, anomenats també macro dades?
La definició de big data és la de dades que:
. contenen major varietat,
. arriben en volums cada vegada més grans i
. es processen amb més velocitat.
Aquesta tríada es coneix també com “les tres V”. (2001. Doug Laney, de Gartner, defineix les 3 V’s del Big Data)
En poques paraules, big data o macro dades són conjunts de dades més grans i complexes, especialment procedents de noves fonts de dades. Aquests conjunts de dades són tan voluminosos que el programari tradicional de processament de dades simplement no els pot gestionar. Però aquests volums massius de dades es poden utilitzar per resoldre problemes empresarials que abans no s’haurien pogut abordar.
El camp del big data ha evolucionat des de la disciplina de l’anàlisi estadística fins a les actuals tecnologies avançades de data lakes o llacs de dades. En aquest article descriurem com hem arribat fins aquí, els reptes que el big data ha plantejat al llarg del camí i com les organitzacions estan utilitzant els data lakes i com les organitzacions les estan utilitzant per obtenir més valor de les dades que mai .
Les arrels de big data provenen de business intelligence o intel·ligència empresarial, un terme que IBM (PDF) va encunyar el 1958, definint-ho com: «la capacitat d’aprendre les interrelacions de fets presentats de manera que guiïn l’acció cap a un objectiu desitjat (IBM, 1958).
Durant els anys 60 i 70, va haver-hi un gran progrés en la tecnologia de dades amb el sorgiment dels mainframes i les bases de dades. A mitjans dels anys 80, els ordinadors personals es van popularitzar i es va introduir la informàtica client-servidor, fet que va portar a l’ús de bases de dades relacionals i a l’aparició del llenguatge SQL (Structured Query Language). Amb aquests avenços, tant la utilitat com el volum de dades van augmentar. A principis dels anys 90, el creixement d’Internet, el comerç electrònic i les tecnologies de cerca van impulsar la recopilació de dades. La necessitat d’intel·ligència empresarial enmig d’aquests grans volums de dades va portar les empreses a crear magatzems de dades especialitzades i optimitzades per a l’analítica. Aquests magatzems de dades es van utilitzar per emmagatzemar dades revisades procedents d’una àmplia varietat de fonts.
Actualment, els magatzems de dades s’han convertit en la infraestructura bàsica que utilitzen les empreses per completar informes, fer anàlisis, fer prediccions i prospectiva empresarial, i donar suport a la presa de decisions sobre evidències observades.
1.3 L’ era actual: explorant dades per a obtenir informació
Al 2005, vam començar a reconèixer la quantitat de dades que els usuaris generaven a través de les xarxes socials i altres serveis en línia. Aquesta gran quantitat de dades, derivades de l’enorme augment de la informació a internet, tant estructurades com no estructurades, eren massa per a les tecnologies existents i per processar-les de manera útil i econòmica. Per tot això, van sorgir diverses iniciatives que intentaven superar les limitacions creixents en l’extracció de dades i la interpretació informativa.
- Google va desenvolupar un nou enfocament anomenat MapReduce, que permetia el processament de grans quantitats de dades. Amb el temps, això va evolucionar a Hadoop, un marc de codi obert que permetia l’emmagatzematge i el processament de dades a gran escala.
- Hadoop, per la seva banda, va permetre la creació de nous usos per a les dades, com ara la creació de vistes completes dels clients en el comerç electrònic. A més, Hadoop es va expandir amb eines addicionals per millorar-ne la capacitat i l’eficiència.
- Posteriorment, Spark es va fer popular per la velocitat de càlcul, escalabilitat i programabilitat per al processament de grans volums de dades, especialment en aplicacions de streaming de dades, grafs, aprenentatge automàtic i intel·ligència artificial. A més, Spark processa les dades en memòria, cosa que permet un rendiment més ràpid i eficient.
2. El món actual i el big data
A la societat d’avui, el big data és un factor important que està influint en molts aspectes de les nostres vides. A causa de la quantitat d’informació que generem a través de les xarxes socials, serveis en línia i altres mitjans, hi ha una gran quantitat de dades disponibles per ser processats i analitzats. La tecnologia ha avançat per poder gestionar aquests grans volums d’informació, cosa que ha permès a les empreses i organitzacions prendre decisions més informades i millorar-ne els processos. A més, la intel·ligència artificial i l’aprenentatge automàtic s’utilitzen cada vegada més per analitzar i utilitzar aquestes dades. No obstant això, també hi ha preocupacions legals i de privadesa, com la regulació de la Unió Europea sobre protecció de dades personals (REGLAMENT 2016/679 DEL PARLAMENT EUROPEU I DEL CONSELL de 27 d’abril de 2016). En resum, el big data és una part integral del món on vivim i està tenint un impacte significatiu en molts aspectes de la societat.
És difícil tenir una visió completa sobre com s’està utilitzant el big data actualment a causa de la gran quantitat de tecnologies i aplicacions que existeixen. No obstant això, hi ha diversos factors clau a la indústria actual, incloent-hi la tecnologia actual, la normativa GDPR i l’aprenentatge automàtic i la intel·ligència artificial.
2.1 Dades, informació i coneixement
Es importante conocer y distinguir las diferencias entre estos tres conceptos clave para el big data:
- Datos: Representan hechos, cifras o estadísticas que no tienen contexto ni significado propio. Son la materia prima para crear información. Por sí solos, no brindan conocimiento alguno.
- Información: Son los datos organizados, analizados y presentados de una manera que los hace significativos y útiles para los usuarios. Proporcionan contexto y permiten entender relaciones y patrones.
- Conocimiento: Es el resultado de combinar información con experiencia, valores, habilidades y juicio crítico. Es el entendimiento profundo y aplicado que se obtiene a partir de la información y permite la toma de decisiones y la resolución de problemas.
Todos estos términos tienen una relevancia importante al interpretar la información en el mundo del big data.
Hay un costo entre convertir datos en información, e información en conocimiento.
En el mundo big data, la cantidad de datos ha explotado de forma exponencial, pero no siempre más datos significa más información. Se ha producido también el efecto contrario, el de la desinformación. La posibilidad de generar datos también ha permitido a ciertas personas generar desinformación.
A la vez que se genera información, esta puede ser usada como entradas de datos para producir más información en conjunción con otros sistemas de información.
La capacidad de generar conocimiento también se verá incrementada, posibilitando generar más conocimiento. Todo esto combinado nos permite crear sistemas que tienen capacidad de predecir tendencias, cruzar la información de formas nunca vistas y generar conocimiento de una forma nunca antes vista.
A dónde llegaremos es algo que aún no está claro, pero la potencia de cálculo sigue creciendo y las expectativas llevan a crear un sistema de inteligencia artificial que supere a la de un humano.
És important conèixer i distingir les diferències entre aquests tres conceptes clau per al big data:
- Dades: Representen fets, xifres o estadístiques que no tenen context ni significat propi. Són la matèria primera per crear informació. Per si sols, no brinden cap coneixement.
- Informació: Són les dades organitzades, analitzades i presentades d’una manera que les fa significatives i útils per als usuaris. Proporcionen context i permeten entendre relacions i patrons.
- Coneixement: És el resultat de combinar informació amb experiència, valors, habilitats i judici crític. És l’entesa profunda i aplicada que s’obté a partir de la informació i permet la presa de decisions i la resolució de problemes.
Tots aquests termes tenen una rellevància important en interpretar la informació al món del big data.
Hi ha un cost entre convertir dades en informació i informació en coneixement.
Al món big data, la quantitat de dades ha explotat de forma exponencial, però no sempre més dades significa més informació. També s’ha produït l’efecte contrari, el de la desinformació. La possibilitat de generar dades també ha permès a certes persones generar desinformació.
Alhora que es genera informació, aquesta pot ser usada com a entrades de dades per produir més informació en conjunció amb altres sistemes dinformació.
La capacitat de generar coneixement també es veurà incrementada, possibilitant generar més coneixement. Tot això combinat ens permet crear sistemes que tenen capacitat de predir tendències, creuar la informació de formes mai vistes i generar coneixement d’una manera mai abans vista.
On arribarem és una cosa que encara no és clara, però la potència de càlcul continua creixent i les expectatives porten a crear un sistema d’intel·ligència artificial que superi la d’un humà.
2.2. Evolució tecnològica i eines d’interès
Apache Flink i Apache Spark són dues plataformes de processament de big data que sutilitzen comunament en la indústria. Ambdues plataformes permeten el processament distribuït de grans volums de dades en temps real i en lots, cosa que permet a les empreses analitzar i obtenir informació valuosa a partir d’aquestes dades. Flink és un motor de flux de dades de codi obert que sutilitza per processar grans volums de dades en temps real. Flink és molt eficient en termes de temps dexecució i escalabilitat, el que ho fa ideal per a aplicacions que requereixen una resposta ràpida i una escalabilitat sense interrupcions.
Spark, daltra banda, és un marc de processament de dades de codi obert que sutilitza per processar grans volums de dades en temps real i en lots. Spark és conegut per la seva capacitat de processar dades en memòria, cosa que el fa ideal per a aplicacions que requereixen una velocitat de processament ràpida. Spark també ofereix una àmplia gamma d’eines i llibreries per a l’aprenentatge automàtic, l’anàlisi de dades i la intel·ligència artificial, fet que ho fa una plataforma atractiva per als usuaris que busquen solucions completes per al processament de big data.
En resum, tant Flink com Spark són plataformes efectives per al processament de Big Data, cadascuna amb les seves pròpies fortaleses i debilitats. L’elecció entre l’una i l’altra depèn de les necessitats específiques d’una empresa i de l’ús que se us donarà a les dades.
2.3 La intel·ligència artificial en la generació de llenguatge natural
El big data o les macro dades, i l’aprenentatge automàtic (conegut com Machine Learning, ML, en anglès) són àrees que es complementen i poden aprofitar-se mútuament. El big data proporciona una gran quantitat de dades per entrenar models daprenentatge automàtic, mentre que els models daprenentatge automàtic poden ajudar a extreure valor de les dades de big data.
Per exemple, amb un gran conjunt de dades de compres en línia, un model daprenentatge automàtic podria analitzar patrons en les compres per fer recomanacions personalitzades per als clients. També podria ajudar a detectar patrons fraudulents a les transaccions de pagament.
Per exemple:
a) La gestió de dades descolarització i la prospectiva en la planificació educativa.
b) La recollida de dades de resultats acadèmics i propostes de polítiques educatives de suport a certes àrees curriculars.
c) La identificació de variables sociofamiliars i la correlació amb el fracàs escolar, l’abandó d’hora o l’absentisme escolar.
Pel que fa a l’ús de la Intel·ligència artificial a l’aula, en els darrers mesos destaca el desenvolupament dels sistemes conversacionals, a partir d’algorismes que detecten freqüències d’ús i patrons lingüístics, com el GPT-Chat. Actualment ChatGPT-3.5 es troba en procés d’aprenentatge i desenvolupament: és un model de llenguatge entrenat per OpenAI que pot ser utilitzat per respondre preguntes i fer tasques comunicatives complexes (p.e. explicar, comparar, preguntar, resumir, sintetitzar, crear respostes personalitzades o adaptades a perfils d’edat, estils lingüístics o preferències culturals diferents).
En aquesta línia de desenvolupament, ChatGPT pot simular en les respostes, amb cert èxit, una adaptació al context proporcionat per l’usuari (el “prompting”), i emetre propostes originals ajustades a diferents paràmetres que ha de donar l’usuari (p.e. utilitzar diversos idiomes , escriure com un autor concret, explicar conceptes matemàtics amb exemples de la vida quotidiana, utilitzar argots o restriccions de lèxic, proposar preguntes d’examen, suggerir regals per a una persona determinada, proposar noms per a un fill, respondre a situacions simulades, etc.) Encara que no és un model d’aprenentatge automàtic específicament dissenyat per processar big data, pot ser utilitzat per respondre preguntes relacionades amb big data i aprenentatge automàtic, ja que ha estat entrenat amb una gran quantitat de text i té coneixement en diversos temes, incloent-hi big data i aprenentatge automàtic.
3- Experiència pràctica: un cas real
La indústria del big data es mou de manera privada i discreta. És difícil descriure un cas d’ús real a causa dels acords de confidencialitat, però intentarem descriure un exemple que s’ajusti a aquest camp de coneixement.
En aquest article ens centrarem en la gestió empresarial del mateix big data, atès que la procedència parteix d’aquest sector i una millor comprensió i contextualització per part del lector. Tot i així, s’abordarà l’enfocament educatiu des de l’article de big data en Educació de la Comunitat Autònoma d’Andalusia, en què veurem com aquest concepte empresarial s’incorpora al món educatiu i la potencialitat que des del nostre àmbit podem trobar en aquest concepte.
Imagineu que fem servir una botiga en línia que ven diversos articles. Coneixem les interaccions dels usuaris amb la pàgina web, la navegació, opinions i historial de compres. A més, tenim prou informació de l’usuari per segmentar-lo basant-nos en la seva edat, ubicació, horaris d’ús i dades demogràfiques. El sistema també és multilingüe, cosa que planteja desafiaments en la identificació de patrons a causa de diferències culturals. En resum, tenim una gran quantitat d’informació que és difícil de definir i abastar a causa de la complexitat i la varietat de dades que es generen (les tres V). Què podem fer amb aquesta informació per millorar les vendes?
1- Coneix les teves mètriques
És la importància de comprendre i mesurar les dades i els indicadors clau que es relacionen amb l’exercici i l’èxit d’una empresa o projecte. És a dir, és una invitació a identificar i seguir de prop els números i les estadístiques que ajudin a entendre la salut i el progrés d’un negoci, per tal de prendre decisions més informades i ajustar estratègies en conseqüència. En resum, conèixer les teves mètriques significa tenir una visió clara i objectiva de la situació actual, cosa que és fonamental per assolir els teus objectius i assolir un creixement sostenible.
Aquesta tasca es pot fer de manera parcial, però és poc realista que un sistema de big data es pugui construir sense tenir els coneixements bàsics del negoci.
2- Segmentació de clients
.La segmentació de clients és un procés que consisteix a dividir un grup de consumidors en subgrups amb característiques similars per comprendre millor i satisfer les seves necessitats i preferències. Això s’aconsegueix mitjançant l’anàlisi de dades demogràfiques, patrons de comportament de compra, preferències i altres factors rellevants.
3- Predicció del valor de vida del client
La predicció del valor de vida del client (CLV, per les sigles en anglès) és una tècnica d’anàlisi que s’utilitza per estimar la quantitat de diners que un client generarà a una empresa durant tot el seu cicle de vida. Aquesta predicció es basa en una varietat de factors, incloent-hi la freqüència i la mida de les compres, la durada de la relació amb el client, la probabilitat de retenir el client i la probabilitat que recomani a altres persones l’empresa. Conèixer el CLV d’un client és important perquè permet a les empreses prendre decisions informades sobre com invocar en un client i com maximitzar-ne el valor per a l’empresa al llarg del temps.
4- Predicció de cancel·lació
La predicció de cancel·lació és el procés d’identificar els clients que tenen una alta probabilitat de cancel·lar un producte o servei en un futur proper. Això s’aconsegueix analitzant patrons de comportament, dades demogràfiques i altres factors rellevants. La predicció de cancel·lació permet a les empreses prendre mesures proactives per retenir els clients i prevenir la pèrdua d’ingressos.
5- Predicció del dia de compra següent
La predicció del dia de compra següent és un procés en el qual s’utilitzen dades de l’historial de compra dels clients, patrons de comportament i altra informació rellevant per predir amb precisió el dia en què un client és més probable que faci una compra al futur. Això permet a les empreses planificar i optimitzar les seves estratègies de màrqueting i vendes per aprofitar al màxim les oportunitats de compra i millorar-ne la relació amb els clients. La següent predicció del dia de compra és una eina valuosa per millorar l’eficiència i l’efectivitat de les operacions comercials.
6- Predicció de vendes
La predicció de vendes és el procés d’utilitzar dades històriques, anàlisis i algorismes d’intel·ligència artificial per estimar les vendes futures d’un producte o servei. Aquest procés pot ajudar les empreses a planificar la seva producció, emmagatzematge i pressupost de màrqueting. A més, també pot ajudar a identificar tendències i oportunitats de creixement al mercat. La precisió de la predicció de vendes depèn de la qualitat i la quantitat de dades disponibles i de l’eficàcia dels algorismes utilitzats.
7- Models de resposta del mercat
Els models de resposta del mercat són eines d’anàlisi que permeten predir la resposta del mercat a una acció específica, com ara una campanya de màrqueting, un augment de preus o un canvi en l’oferta de productes. Aquests models utilitzen tècniques estadístiques i d’intel·ligència artificial per analitzar dades de mercat i del comportament del consumidor, i després fer prediccions sobre com reaccionaran els consumidors a diferents estratègies de màrqueting. Els models de resposta del mercat poden ser útils per prendre decisions informades sobre el posicionament de productes, la segmentació de mercat i la planificació de la demanda.
8- Modelatge d’augment
El modelatge daugment és una tècnica danàlisi de màrqueting que sutilitza per predir quins clients són més propensos a respondre positivament a una campanya de màrqueting i quin impacte tindrà en els seus comportaments de compra. Això s’aconsegueix en comparar el comportament dels clients que van rebre la campanya amb aquells que no la van rebre, cosa que permet identificar els efectes nets de la campanya a les compres i les conversions. El modelatge daugment és útil per maximitzar limpacte de les inversions en màrqueting i millorar leficiència de la campanya.
4. Com es poden implementar aquests processos?
Hi ha diversos algorismes rellevants per gestionar les macro dades que ens ajuden a identificar, predir i prendre decisions sobre les conductes dels usuaris de qualsevol servei.
4.1. Els algorismes rellevants de processos de modelatge de conducta i estudi d’usuaris
Hi ha sis tipus importants d’algorismes d’aprenentatge automàtic: algoriames explicatius, algorismes de mineria de patrons, algorismes d’aprenentatge en conjunt, algorismes d’agrupament, algorismes de sèries temporals i algorismes de similitud.
Algorismes explicatius
Aquests algorismes ajuden a identificar les variables que tenen un impacte significatiu en el resultat dinterès. Permeten entendre les relacions entre les variables al model, en lloc de només utilitzar el model per fer prediccions sobre el resultat. Exemples inclouen Regressió Lineal/Logística, Arbres de Decisió, Anàlisi de Components Principals, LIME i Shapley.
Algorismes de mineria de patrons
Aquests algorismes es fan servir per identificar patrons i relacions dins un conjunt de dades. Exemples inclouen l’algorisme Apriori, Xarxes Neuronals Recurrents, LSTM, SPADE i PrefixSpan.
Algorismes d’aprenentatge en conjunt
Aquests algorismes combinen les prediccions de múltiples models per fer prediccions més precises que qualsevol dels models individuals. Exemples inclouen Random Forest, XGBoost, LightGBM i CatBoost.
Algorismes d’agrupament
Aquests algoritmes s’utilitzen per agrupar dades similars junts. Exemples inclouen K-Means, Hierarchical Clustering i DBSCAN.
Algorismes de sèries temporals
Aquests algorismes es fan servir per analitzar i predir patrons en dades temporals. Exemples inclouen ARIMA i SARIMA.
Algorismes de similitud
Aquests algorismes es fan servir per mesurar la similitud entre les dades. Exemples inclouen KNN i SVM. És fàcil trobar documentació, exemples de qualsevol d’ells a internet. Aquest és un canvi subtil de l’era actual, juntament amb la complexitat d’aquests algorismes, és fàcil trobar implementacions, algorismes adaptats i propostes híbrides.
Una cosa que no s’esmenta en aquest article és el codi obert. No obstant això, quan es tracta de grans quantitats de dades, hi ha una gran quantitat d’informació disponible, que donaria per a un altre article.
Bibliografia i enllaços relacionats
BM(1958). The Reservoir of Information for Control Units. Proceedings of the Eastern Joint Computer Conference, 12, 101-112.
Apache Spark. (s. f.). Apache Spark.
Apache Flink. (s. f.). Apache Flink.
Descarregar PDF de l’Informe. Informe-Tendencias-ODITE-2022.pdf (79742 downloads )